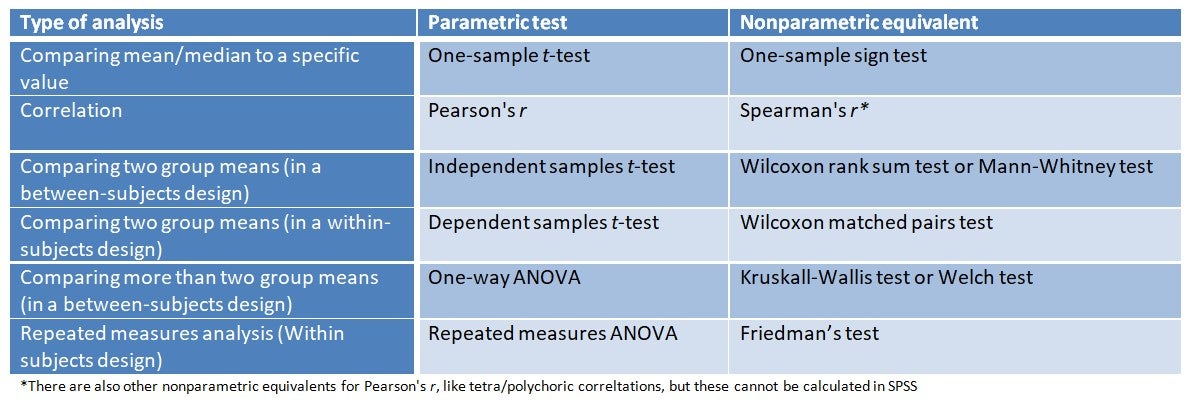
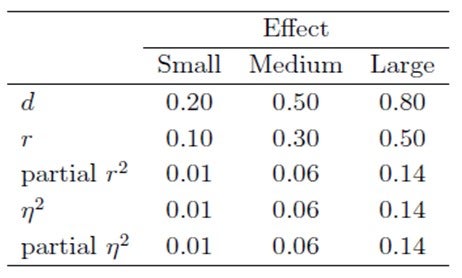
When and how should I categorize data?
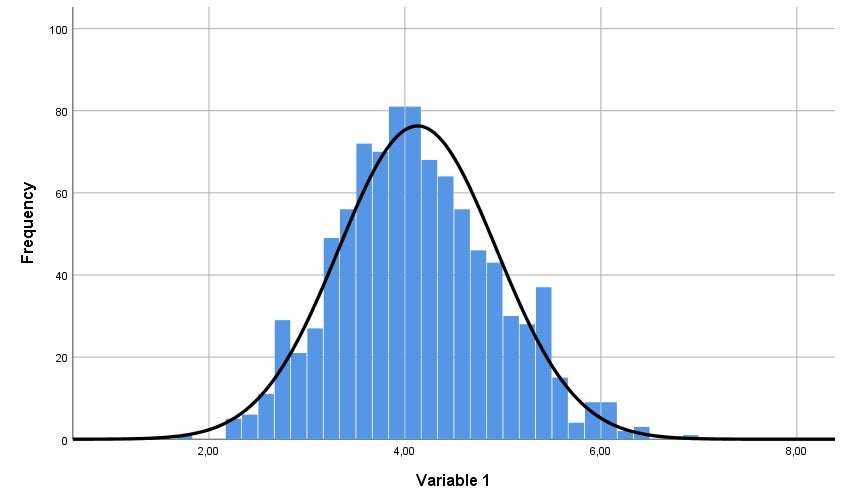
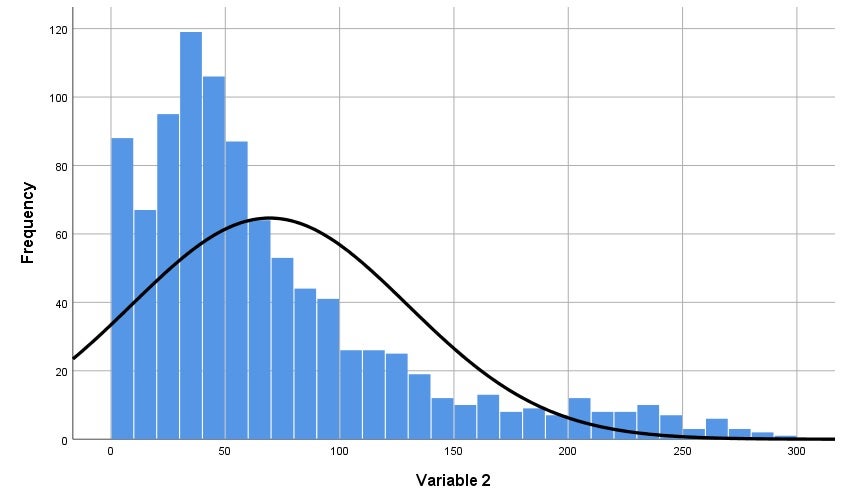
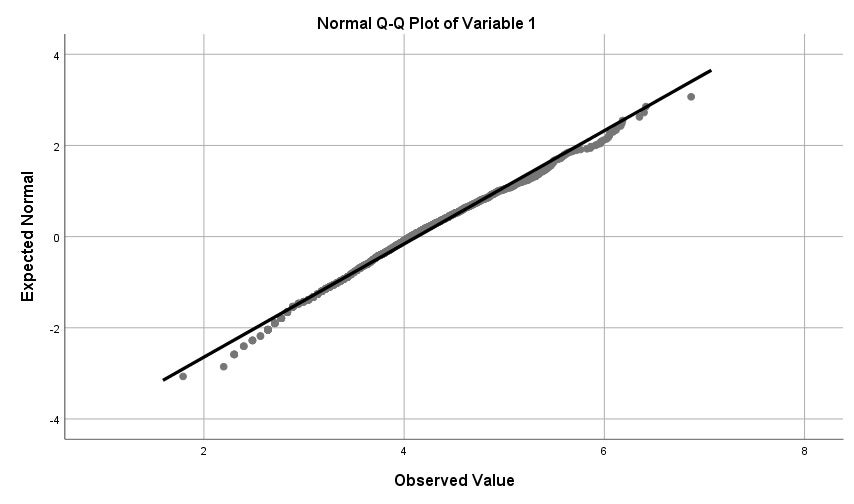
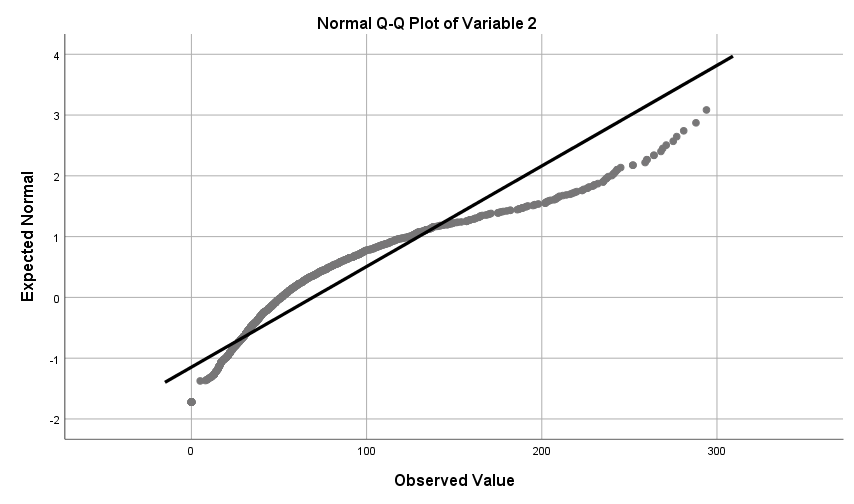
Categorizing (or 'grouping') data means we convert a quantitative variable into a categorical variable. This can be useful for instance when your quantitative outcome variable has severe problems with skewness, and you want to apply a statistical technique that assumes normality. We are going to take the variable delinquent behaviour as an example. This is a variable that is typically severely skewed to the right in samples; the majority of respondents generally report no (or very little) delinquent behaviour, whereas a few respondents will report a lot of delinquent behaviour. Since in this situation the assumption of normality of the data has been violated, recoding the variable into separate groups can be a solution to solve this problem. Other reasons for categorizing data are to help visualize an interaction between two quantitative predictors in multiple regression analysis, or when there is a clear theoretical ground for creating distinct groups of people based on a meaningful break point (e.g., grouping of 'depressed' versus 'not depressed' based on a cut-off score on a quantitative scale).
Categorizing can be done in different ways. The most commonly used techniques are 1) the use of percentile scores, 2) median split, and 3) the use of pre-specified categories.
1. Percentile scores. One option to create groups is by using percentile scores. You could for instance ask SPSS to calculate quartiles, and thereby creating four different subgroups.
To create a new variable based on quartiles, go to:
- Transform > Rank Cases;
- Place the relevant variable(s) in the Variable (s) field;
- Click on Rank Types;
- Remove the check from 'Rank' and instead check Ntiles:4, and click on Continue;
- Click on 'Paste' and 'run' the syntax.
The new variable will appear on the rightmost column in the Data View, and on the bottom row in the Variable View. The new variable represents the four ranks; if a specific value on the original variable falls within the 25% lowest scores, then this case gets a value '1' here, all scores that fall between the 25% and 50% of the lowest scores receive the value '2', etc. The original variable is thus converted into a categorical (ordinal) variable.
One of the uses of creating quartiles, is to make an interaction between two quantitative predictors visible. If this is your goal, then after you have converted one of the two quantitative predictors (or both) into quartiles, you can create a scatterplot in SPSS based on the new categorical variable.
To create the plot, go to:
- Graphs > Legacy Dialogs;
- Choose Simple Scatter and click 'Define';
- Place the quantitative predictor on the X-axis, the outcome variable on the Y-axis and the new categorical (quartile) variable in the box 'Set markers by', and then click on 'OK'.
The graph will now be displayed in the output file.
- Double click on the figure, so the chart editor will open;
- Click on 'Elements' and 'Fit Line at Subgroups', and then close the chart editor.
(Note that there are also other ways to make an interaction between two quantitative predictors visible; either by using the Process module or through Modgraph. This latter option is a program to visualize/plot an interaction between two quantitative predictors. For this program you need to fill in relevant output values (like the mean and standard deviation of the predictors, and the regression coefficients), and then a graph will be drawn for you based on these values. You can access this program through: https://psychology.victoria.ac.nz/modgraph/modgraph.php)
2. Median split. With a median split you can convert a quantitative variable into a dichotomous variable (a categorical variable with only two possible values), based on the median of the variable in question. All values below the median then fall into one category, and all values above the median into another category. For an instruction on the median split technique in SPSS, go to: https://www.youtube.com/watch?v=B0nGVnQYy7k
3. Pre-specified categories. With pre-specified categories, you decide beforehand which scores will fall into a certain category (instead of letting the data decide the categories, like with median split or percentile scores). For instance, you can make different age groups (e.g., 10-19: adolescents, 20-64: adults, >64: seniors), based on logical pre-established distinctions. A challenge with this option is how to decide the specific ranges of each group, in the absence of a theoretical rationale. If there is no clear theoretical rationale, it is advised to use percentile scores or the median split option instead.
Categorization with pre-specified categories can be conducted in SPSS through the Compute command (Go to: 'Transform' --> 'Recode into different variables'). For a comprehensive instruction on how to categorize a variable, watch the following video: https://www.youtube.com/watch?v=nJ6nxRXRTHc
Note that categorizing variables can (and in most cases will) have consequences for the type of statistical technique you can use to test your hypothesis. Moreover, a disadvantage of categorizing variables, is that you 'lose' information, because you are grouping people or cases together, who might be very different from one another. By putting these cases together in one category, you cannot make a distinction between these cases anymore in your analysis. This typically results in a loss of power. Therefore, always make sure you have a legitimate reason to categorize a quantitative variable.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}